In C# you can add folding points to the code file by using the #region directive. The question of how and when (if ever) to use this feature is an endless debate among C# developers. Some find it useful for grouping members with related functionality or by accessibility level, some just hate them.
My personal opinion is that regions are pretty much useless. When I open a file in the editor I expect to see the code. Not a bunch of gray text blocks, which is the default behavior in Visual Studio. Hiding generated code that is never to be touched or non-implemented members from a poorly designed abstract base class with too many responsibilities, are a couple of use cases that I think are justified. A few years ago I found out that you could disable folding/outlining by navigating to tools > options > text editor > c# > advanced and uncheck the Enter outlining mode when files open option. I’ve left it like that ever since. There is also the I Hate #Regions Visual Studio extension that does the same thing, more or less.
The regionalize everything style
I recently inherited an ASP.NET MVC project where the C# code uses an interesting region pattern. Every member of a class is surrounded by a region, where the region label matches the signature of the member. The regions were generated by a macro together with XML documentation comments for the members.
1 2 3 4 5 6 7 8 9 10 11 | |
Except for the regions I’m OK with documentation comments. Good documentation comments on the public members of an API is very nice to have since the intellisense picks them up and you can see it inline while coding.
However, in this codebase many comment elements are left empty, adding a lot of meaningless noise to the code. Another annoyance as seen in the somewhat contrived example is that when the method has been refactored, the region label and comments have not been updated.
This kind of region (mis)use is way to obtrusive to me, so I decided to clean it up.
The cmdlet
What we want to do is remove all regions and empty documentation comments from the C# files of the solution. Sounds like a perfect time for me to learn how to make a Powershell cmdlet that processes pipeline input. The goal is to be able to write something like this:
> ls c:\myproject -r -i *.cs | remove-regions
That is, get all descendant .cs files of a directory and pipe them into the remove-regions cmdlet.
After a little experimenting I ended up with this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
The CmdletBinding attribute adds some useful capabilities to the function, e.g. by setting the SupportsShouldProcess flag to true we can use the -WhatIf and -Confirm switches when calling our cmdlet.
In the Parameter attribute we specify that $Filename is a required parameter that accepts input from the powershell pipeline. The other parameter - $Encoding - has the default value UTF8 and sets the output encoding used when writing the modified file.
In order to match and replace the offending lines in the file I need to dust off my old regex-fu.
Decoding the regex
The regular expression looks like this:
\s*(?:#(?:end)?region|///\s*<([^/\s>]+).*?>[\s/]*?</\1>).*
The expression starts off by trying to match \s* - zero or more whitespace. It then enters a non-capturing group (?: where the first alternative #(?:end)?region, tries to match either a #region directive or an #endregion directive.
The second alternative should match empty document comment elements. It does this by first matching the triple slash comment ///\s* used for documentation.
Next comes the start tag <([^/\s>]+).*?>. The tag name is saved in group 1 for future reference and the character class [^/\s>]+ says “match one or more characters that is not a / (we want to match the start tag), a whitespace (not a valid XML-name character) or a > (the tag end.)” Some elements has attributes so we match .*?>, i.e. any character after the name up to the next >.
As we saw in the example earlier, some elements are empty and spanning multiple rows. Therefore, to match the content of an empty element, we use the character class [\s/]*?. I.e. zero or more whitespace (including line breaks) or / characters.
The last thing to match is the end tag of the element, which i done by </\1>. Here we use a back reference to the tag name we captured when we matched the start tag of the element.
Lastly we close the grouping that wraps the expression and match the rest of the line ).*.
The result looks like this in RegexBuddy, my weapon of choice when it comes to constructing and testing regexes.
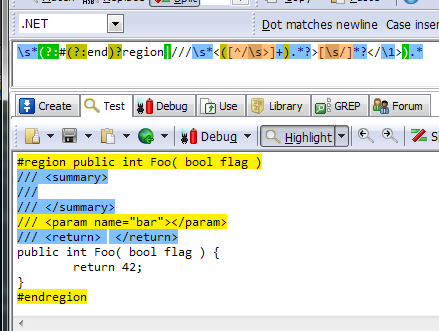
Blue and yellow text are matches to the regex. You can get the code at GitHub if you face similar problems.